2022年8月,在举办的数据挖掘顶会ACM SIGKDD Conference on Knowledge Discovery and Data Mining上,我实验室的杨珉教授和张谧教授等师生将现有仅能应用于分类模型的指纹追溯技术普遍化,提出一种深度学习模型产权追溯通用方法,首次在千级嫌疑模型库上实现100%的盗版模型识别准确度。
近年来,随着深度学习技术的不断发展,神经网络在各领域得到了广泛的应用,而神经网络的知识产权保护也成为了一个重要问题。神经网络模型的训练通常需要大量的计算资源与数据样本,而攻击者可通过系统攻击、算法攻击等方式窃取模型,并施以模型所有权混淆技术,低成本地完成盗版模型的构建。为对盗版的神经网络进行检测,模型指纹成为近年的新兴研究课题(图1)。然而,现有模型指纹追溯技术大多仅能应用于分类模型保护,且易于被适应性混淆攻击绕过。

图 1 模型指纹特征提取流程
为了提升模型指纹技术的通用性,项目组首次将现有指纹追溯技术中的指纹验证样本和验证方法等设计模块进行一般化推广,提出基于适应性指纹验证样本(adaptive fingerprinting examples)和元验证器(meta-verifier)的深度学习模型指纹追溯新方法,将用户构造的多种嫌疑模型融入到模型指纹的构建过程中,从而大幅提升所构造指纹的鲁棒性与有效性,并适用于多种下游任务模型(图2)。
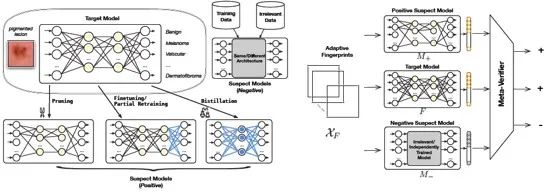
图 2 基于适应性指纹样本和元验证器的新型模型指纹追溯技术
具体而言,项目组利用联合训练自适应指纹和元验证模型,通过嫌疑模型的联合输出来进行模型指纹的检测,适用于多种下游任务模型的知识产权保护:先为目标模型构建多组自适应指纹样本,再检测在嫌疑模型中这些自适应指纹样本的输出是否能通过元验证模型的检测。该指纹检测机制基于嫌疑模型在自适应指纹样本上的输出,而非对抗样本的输出标签,故无关于具体任务类型、不依赖于训练数据,能够广泛应用于各种任务类型的神经网络指纹检测,如分类、回归、生成模型等,以保护神经网络的知识产权,且指纹样本的产生不依赖于训练数据。使用的自适应指纹样本在正、负例嫌疑模型上的输出具有较大的差异,使得元验证模型的输出发生变化,故具有较好的独特性;同时,对于目标模型的后置处理并不能越过元验证模型的分类边界,故具有较好的鲁棒性。
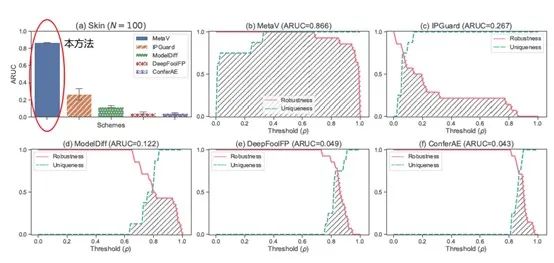
图 3 提出的深度学习模型指纹的追溯能力提升此前最优方法60%以上
实验表明,项目组提出的方法首次实现任意任务类型(包括分类、回归、生成、目标检测、特征提取等多个任务场景)的模型指纹特征提取,在分类任务上,黑盒/白盒指纹综合性能指标均高于现有最优方法60%以上(图3),在超过1000个模型组成的测试集上,能以100%的精度检出多种经过模型量化、蒸馏、剪枝、微调混淆后的正例嫌疑模型。
(转载自 复旦白泽战队公众号)