基于机器学习的恶意软件检测
构建恶意软件检测的机器学习模型,并对其进行评估和优化
实验目标
- 理解恶意软件检测的基本原理和挑战;
- 熟悉常见的机器学习算法和模型,了解它们的优缺点和适用场景;
- 能够构建恶意软件检测的机器学习模型,并对其进行评估和优化。
前置准备
1. 理论知识学习
进行本实验前请先完成教材第8章的理论学习和机器学习、深度学习模型的基本使用。
2. 实验环境
- Python 环境
- 机器学习模型:使用 scikit-learn 库实现
- 深度学习模型:基于 Pytorch 或者 Keras 实现
任务描述
任务1 恶意软件分类
基于给定的移动应用特征数据集,分别利用传统机器学习模型和深度学习模型,设计并训练一个二分类器,用于区分恶意软件和正常软件。你需要在上述两类模型中分别选择至少一种模型来完成本次实验。
1. 评价指标
模型在测试集上的 Precision(精确率),recall(召回率)和 F1-score。本次实验中,正类代表恶意软件,负类代表正常软件。
Precision(精确率):Precision 衡量的是模型预测为正类别的样本中,有多少是真正的正类别样本。计算公式如下:
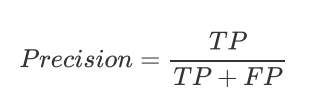
其中,TP 表示真正例(True Positive),即模型将正类别样本预测为正类别的数量;FP 表示假正例(False Positive),即模型将负类别样本预测为正类别的数量。
Recall(召回率):Recall 衡量的是真正的正类别样本中,有多少被模型正确预测为正类别。计算公式如下:
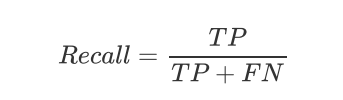
其中,FN 表示假负例(False Negative),即模型将正类别样本预测为负类别的数量。
F1-Score:F1-Score 是 Precision 和 Recall 的调和平均值,综合了两者的性能指标。计算公式如下:
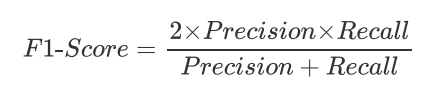
F1-Score 能够同时考虑 Precision 和 Recall,适用于评估模型在不同类别的样本上的性能。
2. 数据介绍和使用要求
共包含3个数据集,分别存放在 train,validation,test 文件夹下。注意,你选择的模型只能在 train 和 validation 数据集上进行训练和验证,test 仅用作模型的最终评估。
数据格式:
- csv 文件存储,每个数据集中都包含 malware.csv 和 benign.csv 两个文件,分别代表恶意软件数据和正常样本数据。需要从这两个文件中读取数据,以获取提取好的软件样本特征。
- 每个样本包含样本名称、标签(恶意样本标签为1,正常样本标签为0)以及 474 个特征数据
特征描述:
| 类别 | 特征 | 数量 | 字段示例 | 描述 |
|---|---|---|---|---|
| 动态 - 系统调用 | 系统调用 | 288 | execve, getuid32, SYS_300 | 应用程序在运行时发出的系统调用集中的每个系统调用的绝对频率 |
| 动态 - 系统调用 | 系统调用总数 | 1 | nr_syscalls | 应用程序在运行时发出的系统调用总数 |
| 静态 - 权限相关 | 标准权限 | 166 | ACCEPT_HANDOVER, WRITE_VOICEMAIL | 二进制特性,表明应用程序是否请求了标准 Android 权限 |
| 静态 - 权限相关 | 标准权限类型 | 3 | normal, dangerous, signature | 请求的正常、危险和签名权限的总数 |
| 静态 - 权限相关 | 标准权限总数 | 1 | nr_permissions | 应用程序请求的标准权限总数 |
| 静态 - 权限相关 | 自定义权限 | 1 | custom_yes | 二进制特性,表明应用程序是否声明了任何自定义权限 |
| 静态 - 权限相关 | 自定义权限总数 | 1 | nr_custom | 应用程序定义的自定义权限总数 |
| 静态 - 文件统计特征 | 文件大小 | 2 | CFileSize, UFileSize | 压缩(apk)文件大小和未压缩的文件大小 |
| 静态 - 文件统计特征 | 文件数量 | 1 | FilesInsideAPK | apk 内的文件数量 |
| 静态 - Activities & Services 统计特征 | 活动和服务总数 | 2 | Activities, NrServices | 应用程序定义的活动总数和服务总数 |
任务2 实现Burp Suite扩展
在该任务中,我们需要实现一个简单的 Burp Suite 扩展,从而能够自动化地实现任务1的目标(即获取两个 secret)。读者可以在 官网 学习 Burp Suite 扩展的知识。
具体来说,我们需要实现两个功能:
- 使用 Burp Suite 扩展修改请求报文(request),使得我们能够在按下“购买”按钮后能够直接获得 flag;
- 使用 Burp Suite 扩展修改响应报文(response),使得我们能够在按下“购买”按钮后可以在当前页面看到 ID。
结果提交形式
- lab7_code.zip:本次实验中的实验代码,需要包含数据预处理以及模型训练和评估的代码
- lab7.docx:本次实验的实验报告,包括实验目标、实验过程、实验结果和实验心得等
评分标准
1. 完成任务1(70%)
分别使用任意一个机器学习模型和深度学习模式完成恶意软件的二分类,各占35%
2. 实验报告(30%)
内容完整性和原创性(20%)
- 报告包含实验目的、详细步骤、结果、总结思考等关键部分
- 代码设计遵循代码规范,有必要的解释说明
报告撰写和表达(10%)
- 报告格式规范,语言表达清晰
- 能够适当使用图表等辅助说明报告内容
实验资源
Lab7 实验资源包
包含本次实验所需的全部资源文件
资源包内容
data.zip
数据集,包含 41,382 恶意样本 & 36,755 正常样本