导语
漏洞治理包括挖掘、分析和修复三个环节。随着挖掘技术的发展,漏洞发现速度显著提升,但分析与修复仍依赖人工,成为主要瓶颈。尤其在Linux内核这类复杂系统中,分析成本高、效率低,因此亟需自动化的漏洞成因分析方法。
本团队聚焦内核中常见且高危的内存破坏漏洞,探索了相应的自动化成因分析技术。本文简要介绍了核心思路与实验结果,更多细节欢迎阅读论文原文并交流探讨。
论文链接:https://yuanxzhang.github.io/paper/kernelRCA-security26-full.pdf
问题剖析
1.为什么内核漏洞成因分析本身很困难?
在分析Linux内核漏洞的成因时,关键在于理解其动态执行过程,即代码如何执行、数据如何传递。分析通常从漏洞报告或内存转储出发,逆推执行路径以还原触发逻辑。但这一过程往往困难重重,关键数据来源不清、关键调用路径模糊,不得不依赖猜测和反复调试,耗时耗力。其根本原因在于两点:
(1)内核大量使用函数指针,实际调用关系难以通过静态阅读确定
(2)数据依赖复杂且隐式,跨线程、跨系统调用传递,使数据流难以追踪。如能有自动化方法直观呈现完整的调用关系和数据依赖,将显著降低分析门槛。
2.现有方法是否适用于内核场景?
现有自动化漏洞成因分析方法包括反向调试、差分调试和特定漏洞建模等,但在内核中效果有限:
- 反向调试依赖从崩溃点逆推,遇到复杂控制流或数据流就难以深入;
- 差分调试依赖大量相似输入,而内核漏洞通常只有单个 PoC,难以满足条件;
- 特定建模方法只适用于特定类型漏洞,缺乏通用性。
3.分析结果是否直观?
现有方法输出通常是孤立的零散信息,例如代码位置或触发条件(谓词)。这些信息缺乏结构,分析人员仍需手动推导并拼接漏洞逻辑,需要进一步花费时间调试和阅读源码。
综上,无论是分析方法还是结果表达,现有技术都难以直接服务于内核漏洞分析。因此,本团队希望设计一种面向内核漏洞的成因分析方法,不仅能完成自动化分析,还能以更直观的方式呈现漏洞发生的动态过程,帮助研究人员快速理解漏洞本质。
方法设计
1. 漏洞成因表示形式的设计
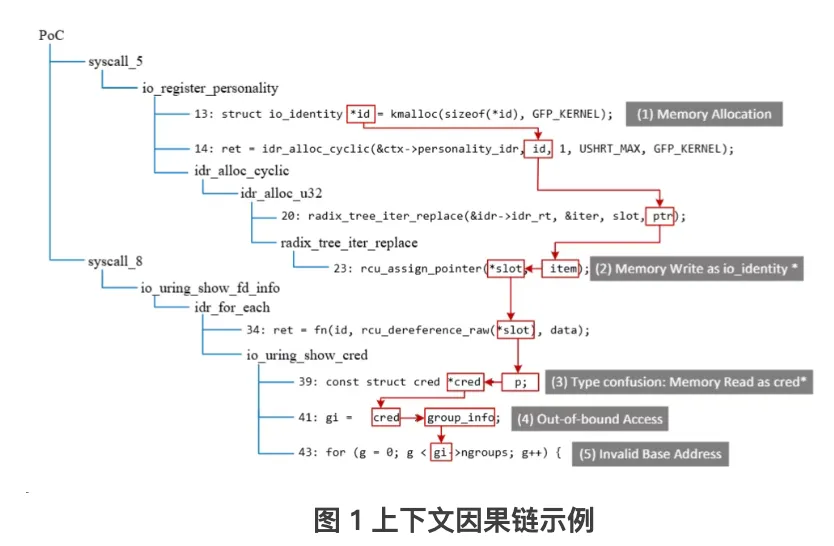
为使分析人员直观理解漏洞发生的动态过程,本研究设计了一种名为上下文因果链(Contextual Causality Chain)的漏洞成因表示形式。上下文因果链包含上下文和因果链两个部分。上下文部分包含了一棵调用树(蓝色边)和数据依赖关系(红色边)。因果链包含了漏洞成因相关指令,以及这些指令对应的行为描述。
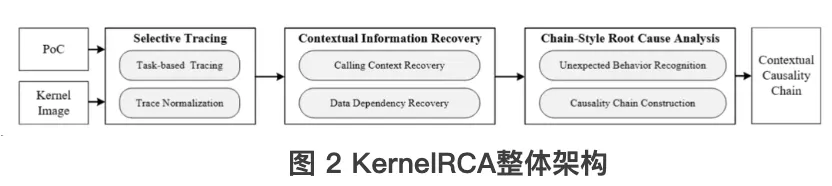
2. 自动化内核漏洞成因分析系统设计
本研究设计并实现了一套面向内核漏洞的自动化成因分析系统KernelRCA。该系统以单个漏洞PoC为输入,通过动态追踪其在内核中的执行过程,重建指令级的完整上下文信息(包括调用关系与数据依赖),并结合典型内核漏洞成因模型,从中识别与漏洞高度相关的关键指令,最终以上下文因果链的形式输出漏洞成因分析报告。
挑战与实现
在系统设计和实现过程中,主要面临以下挑战:
1.全量内核动态追踪开销高
为避免遗漏漏洞成因,对PoC 执行过程进行全量指令级追踪是最直观的做法,但内核代码规模庞大,带来难以接受的时间与空间开销。
基于此,本研究提出了基于感兴趣任务的选择性内核动态追踪方法,仅关注由PoC直接或间接触发的内核任务(如线程、中断、工作队列),并结合任务生命周期进行筛选,从而将追踪范围限制在与漏洞触发高度相关的执行路径上,大幅降低开销。
2.上下文信息重建规模巨大
仅获取二进制执行轨迹难以支撑成因分析,还需为每条指令补充调用关系与数据依赖等语义信息。然而,由于指令数量庞大,若采用简单的方法(逐对依赖分析、逐指令记录调用栈),则开销难以承受。
针对该挑战,本研究设计了一种类模拟的上下文重建方法,按执行顺序模拟指令语义,在线性时间内重建数据依赖;同时以树结构紧凑表示调用上下文,仅维护当前栈帧节点,在函数调用与返回时动态扩展与回退,实现对完整调用关系的线性空间存储。
3.如何从大量指令中精准定位成因指令
与漏洞成因相关的指令通常与崩溃点指令存在直接或间接数据依赖关系,如参与了访存地址计算、偏移计算等。然而,与崩溃点存在数据依赖的指令数量庞大。但真正导致漏洞的仅是其中少部分指令,如何精准对其识别成为挑战之一。
对此,本研究从时间、空间和语义三个维度总结了常见漏洞的异常行为特征,并在重建的上下文中识别这些异常,从而筛选潜在的成因相关指令。在此基础上,本研究进一步设计了动态规划算法,从崩溃点出发寻找包含最多异常行为的数据依赖路径,以期寻找深层漏洞成因,并按发生顺序组织为因果链以解释漏洞成因。
实验评估
本研究选取了65个涵盖六类不同表现形式的内核内存漏洞,对KernelRCA的效果进行了评估。结果表明,KernelRCA能够正确诊断其中54个漏洞的成因,整体有效率约为83%。在性能方面,平均每个漏洞的分析时间为97秒,平均存储开销为1.39GB。这些漏洞成因呈现出一定的共性模式,本研究将其归纳为12类。同一种崩溃表现通常具有多种不同的成因。

进一步的,从成因距离(识别的成因指令到真实成因指令的指令级距离)的角度评估了本方法的优势。KernelRCA生成的平均成因距离仅为内核原生漏洞报告的45.6%。与Syzbot Cause Bisection定位到的漏洞引入代码变更相比,KernelRCA生成的上下文因果链在41个漏洞上具有更近的成因距离。
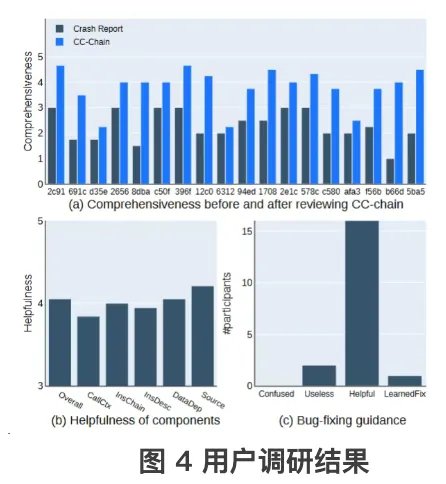
最后,通过问卷调研评估了上下文因果链对漏洞理解的促进作用。在审阅上下文因果链后,分析人员对漏洞的理解评分明显提高。同时,调研参与者普遍认为上下文因果链对漏洞修复具有帮助作用,能够提示关键代码位置及提供修复思路。
讨论与展望
1.漏洞成因的定义与边界
本文所识别的漏洞成因主要聚焦于程序的内存行为层面。然而,分析更高语义层面的成因仍十分困难,例如引用计数异常、状态机状态错误或标志位误用等。这类问题往往依赖对程序功能的深入理解。传统程序分析方法通常需要针对具体问题进行建模,但此类建模方式通用性和扩展性有限。近年来,大语言模型在代码语义理解方面展现出一定潜力,结合智能体等技术,或可为高层语义漏洞成因的自动化分析带来新的思路。
2.从成因分析走向漏洞治理
随着漏洞挖掘和分析自动化水平的提升,仍高度依赖人工的漏洞修复正逐渐成为新的瓶颈。现有自动化修复技术面临的关键挑战之一,正是对漏洞成因理解不准确。本研究提出的方法或可为自动化漏洞修复提供更好的支持,促进自动化内核漏洞修复的相关研究。
作者简介
顾康正,复旦大学计算与智能创新学院系统软件与安全实验室博士研究生,师从张源教授、杨珉教授,研究方向主要为Linux内核安全。相关研究成果发表于安全领域顶级会议USENIX Security、软件工程顶级会议FSE等。
张一帆,复旦大学计算与智能创新学院系统软件与安全实验室博士研究生,师从张源教授、杨珉教授,研究方向主要为固件安全、Linux内核安全等。相关研究成果发表于安全领域顶级会议USENIX Security等。