01
很多时候,漏洞修复会被看作安全工作的终点,当厂商发布漏洞补丁后,一个漏洞似乎就此画上句号。
但从漏洞治理的角度看,修复并不只是“补上一个洞”,它还留下了更有价值的东西:哪些输入是不可信的,哪些操作是危险的,哪些校验真正有效,哪些调用方式会把普通功能变成攻击入口。
问题在于,这些知识往往分散在漏洞公告、补丁、提交记录、PoC 和代码上下文里,难以被系统整理,更难被机器直接使用。于是,大量真实世界中的漏洞经验,并没有真正沉淀成可复用、可迁移、可持续更新的安全规则。
复旦大学系统软件与安全实验室漏洞治理小组正在围绕这一问题开展研究。我们的目标是尝试回答问题:能否将真实世界中的漏洞信息,自动转化为可被机器理解、复用和更新的安全知识?
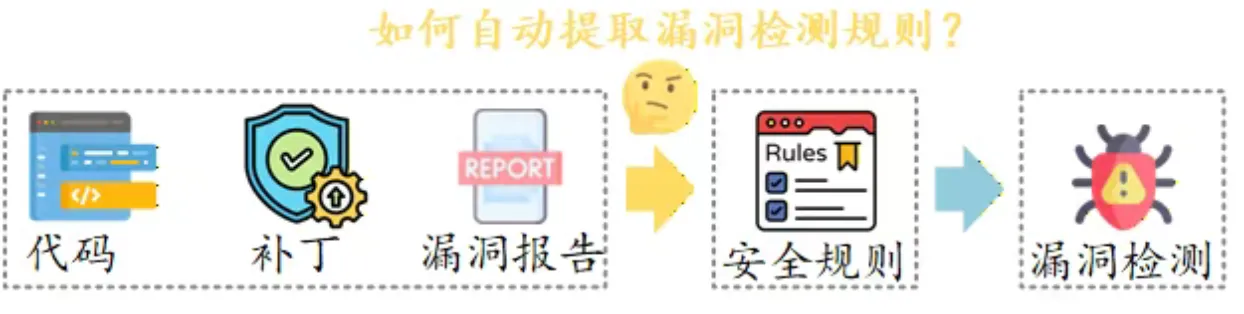
02
漏洞知识与安全规则:为什么重要
从最通俗的角度看,漏洞知识可以理解为一组帮助工具理解并识别漏洞风险的规则。
其中,Source 指不可信输入的来源,例如网络请求参数、上传文件内容或用户可控字符串;Sink 指一旦被不可信数据触达就可能产生安全后果的危险操作,例如表达式执行、文件访问、XML 解析、反序列化或命令执行;Sanitizer 则是位于两者之间的安全检查或净化逻辑,例如白名单校验、路径规范化、危险函数禁用、长度限制或上下文隔离。
如果把漏洞看作一条路径,那么很多安全问题本质上就是:不可信数据从 Source 出发,在缺少有效 Sanitizer 的情况下,最终流入了危险的 Sink。比如,用户输入的表达式如果没有经过限制就被求值,可能引发表达式注入;用户传入的路径如果没有经过规范化就被用于文件访问,可能导致路径穿越;XML 解析器如果没有正确关闭外部实体能力,就可能引发 XXE;反序列化接口如果缺乏对象类型或调用链约束,则可能演变为远程代码执行。
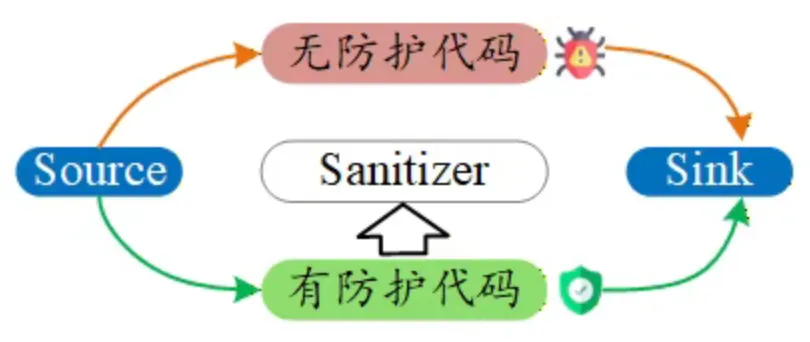
为什么这些规则重要?因为自动化安全分析工具并不会天然具备这类知识。像 CodeQL 这样的工具,本质上依赖规则库来理解哪些输入需要被关注、哪些操作具有高风险、哪些防护逻辑能够阻断攻击。
一旦规则缺失,工具就很容易出现两类问题。一类是漏报:新框架、新组件、新披露的高危 API,或者项目自定义的防御逻辑没有被覆盖,工具即使看到了代码,也未必知道真正的风险在哪里。另一类是误报:工具知道某个 Sink 危险,却识别不出前面的有效校验,于是“逢高危接口必报”。
像 Java 反序列化、表达式注入、路径穿越、XXE 等问题,如果缺少精确的知识支撑,就很难被高质量地挖掘出来。换句话说,漏洞知识与安全规则的重要性,并不只是帮助我们“解释一个漏洞”,更在于决定自动化分析系统能否真正把漏洞找准、找全、找得有用。
提取安全规则:我们解决什么问题
如果规则这么重要,接下来的问题就是:这些规则从哪里来?
长期以来,安全规则往往依赖专家手工总结。研究者阅读漏洞公告、分析补丁、复现漏洞、理解框架机制,再把经验抽象成规则,写进检测器或知识库里。这种方式当然有效,但成本高、更新慢、覆盖有限,也很难跟上不断演化的软件生态。
因此,我们更希望将这件事尽可能自动化。直接从真实世界中已经公开的漏洞信息里,自动提取可被机器使用的安全知识。这里的信息源不只包括补丁,也包括 NVD、CNVD 等漏洞数据库中的描述信息、项目提交记录、安全公告、PoC,以及与漏洞相关的代码上下文。
我们的目标,是把这些分散、异构、半结构化甚至非结构化的材料,逐步转化为规则化、结构化的知识表示。这些知识最终不应只是几条零散结论,而应该形成一套可以持续扩展的规则库。它既包括 Source、Sink、Sanitizer 这类基础规则,也包括更具体的 API 安全约束、利用条件、参考防御,并进一步支撑漏洞检测、漏洞验证和修复建议生成。
然而,漏洞知识天然是分散的,数据库给的是文字描述,补丁给的是代码改动,PoC 给的是利用方式,项目代码给的是真实上下文,它们之间并不是天然对齐的。更重要的是,真实世界中的安全语义常常是隐含的,开发者不会在补丁里直接写下“这里违反了某条安全规则”,更不会把 Source、Sink、Sanitizer 明确标注出来。与此同时,同一类规则还需要跨项目、跨框架迁移,不能只适用于某一个样本。
面向这一挑战,我们希望从补丁、漏洞数据库、公告文本、PoC、提交记录等多种信息中,自动提取 API 安全规则,并完成多源漏洞知识的对齐与融合。在此基础上,进一步推进规则自动识别、自动验证、自动更新,逐步构建可以持续生长的漏洞知识体系。
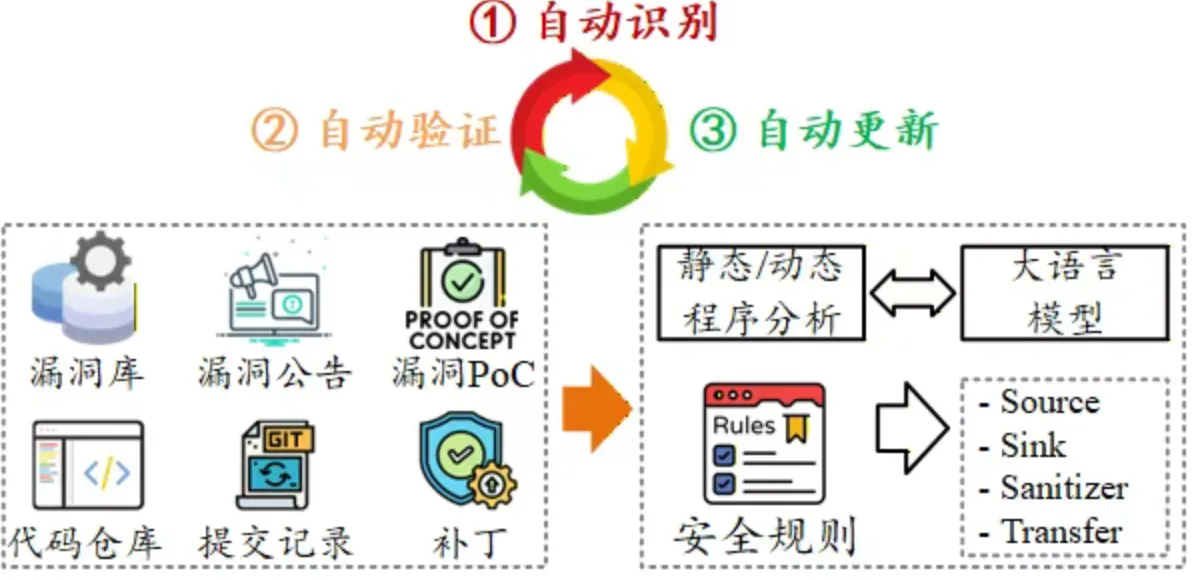
在这个过程中,静态程序分析、动态程序分析和大语言模型各自承担不同角色。静态分析帮助我们理解代码结构、调用关系和数据流约束;动态分析帮助我们确认利用条件和防御是否真正有效;大语言模型则更适合辅助理解补丁语义、漏洞文本和跨文件知识对齐。三者结合,才有可能让“从漏洞到规则”这件事真正落地。
03
初步成果:从补丁中提取 API 安全规则
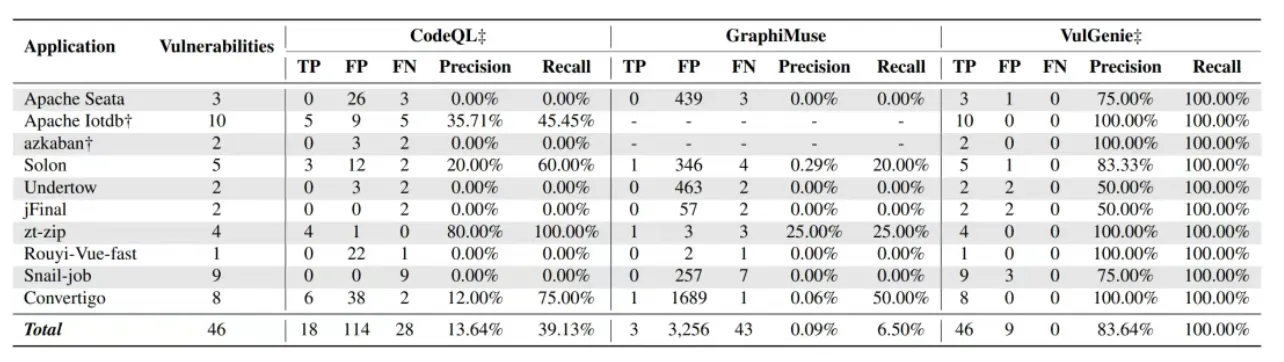
围绕这一方向,我们先从安全补丁出发,设计了 VulGenie。它面向 Java 安全补丁,自动识别补丁中被违反的安全约束和修复时引入的参考防御,再把这些信息沉淀为可迁移的 API 安全规则,并进一步用于发现 API 误用漏洞。

VulGenie 在 150 个近期披露的 Java 安全补丁上共提取出 198 条正确的 API 安全规则,精度达到 81.82%;其中 177 条规则是现有 CodeQL 知识库中尚未覆盖的。
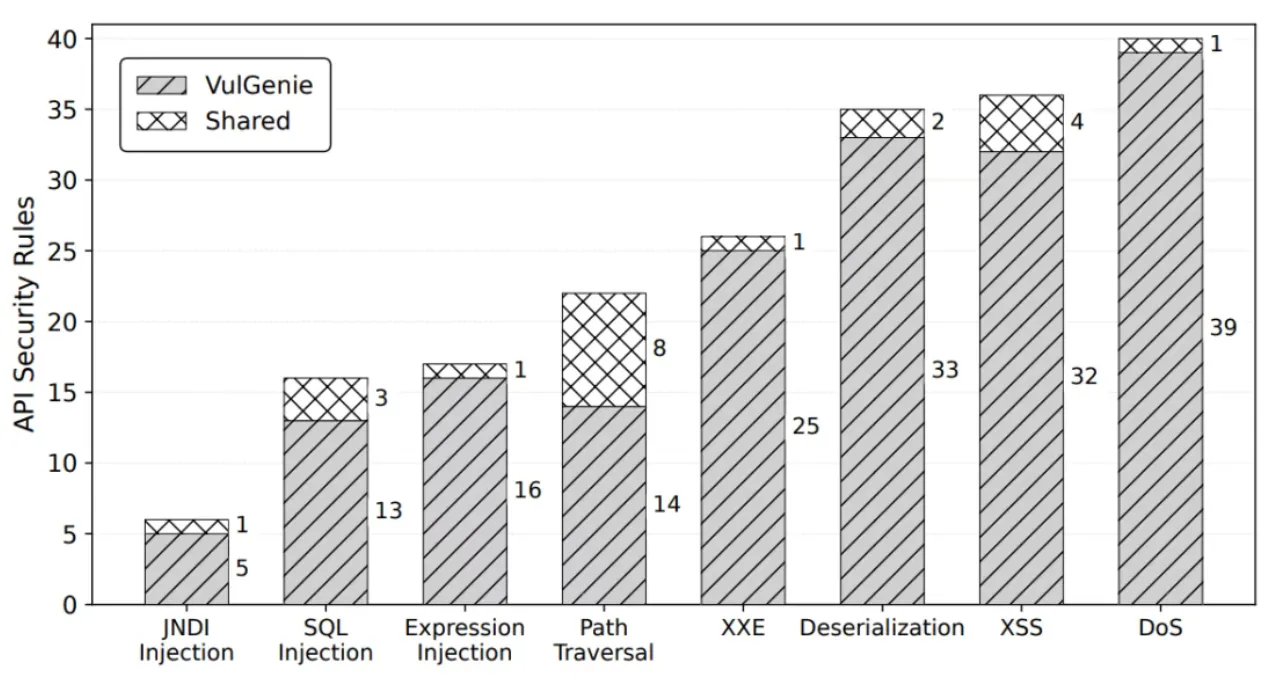
基于这些规则,研究团队又在 10 个流行 Java 应用的最新版本中发现了 46 个 0-day 漏洞;其中 26 个漏洞已完成修复,10 个漏洞被分配了 CVE 编号。相关成果已被 USENIX Security 2026 接收。
未来,如何把补丁、漏洞数据库、公告文本、PoC、提交记录与代码分析更紧密地结合起来,仍然是我们接下来要继续推进的方向。
04 研究团队
张磊,复旦大学助理研究员,主要研究方向为漏洞挖掘与治理,目前主持国家重点研发计划子课题、国家自然科学基金青年基金、上海市人民政府决策咨询项目等,在 IEEE S&P、ACM CCS 等网络安全顶会上发表论文十余篇,获上海市科技发明一等奖、上海 CCF 科学技术一等奖、ACM SIGSAC 中国优博奖和 ACM 中国优博提名奖,并获得 2022 年 USENIX Security 杰出论文奖、2024 ACM FSE 杰出论文奖等。多项研究工作以内参、专报等形式上报政府相关部门,多次获得党和国家主要领导人批示,发现的某关键漏洞获 CNVD 最具价值漏洞奖,并多次配合相关部门开展工作。
陈波妃,复旦大学计算与智能创新学院博士研究生。主要研究方向为Java漏洞挖掘、程序分析与软件安全等,在IEEE S&P、USENIX Security、ASE等国际会议上发表多篇学术论文,相关研究涵盖Java反序列化利用链检测、API安全规则提取、补丁迁移以及大语言模型辅助程序分析等方向。
廖双,复旦大学计算与智能创新学院博士研究生。主要研究方向为PHP漏洞挖掘、程序分析等,在USENIX Security等国际会议上发表多篇学术论文,相关研究涵盖补丁分析、漏洞PoC自动生成以及PHP Web漏洞挖掘等方向。