《来自微软研究院的2026年前沿观察》指出,AI 正从自动化迈向自主化。这意味着,AI 系统已不再局限于指令执行,而是进化为目标驱动的智能体(AI Agent)。在工具调用能力的支持下,智能体能够形成从目标理解、任务拆解到自主决策与执行反馈的完整闭环,自主完成复杂任务。
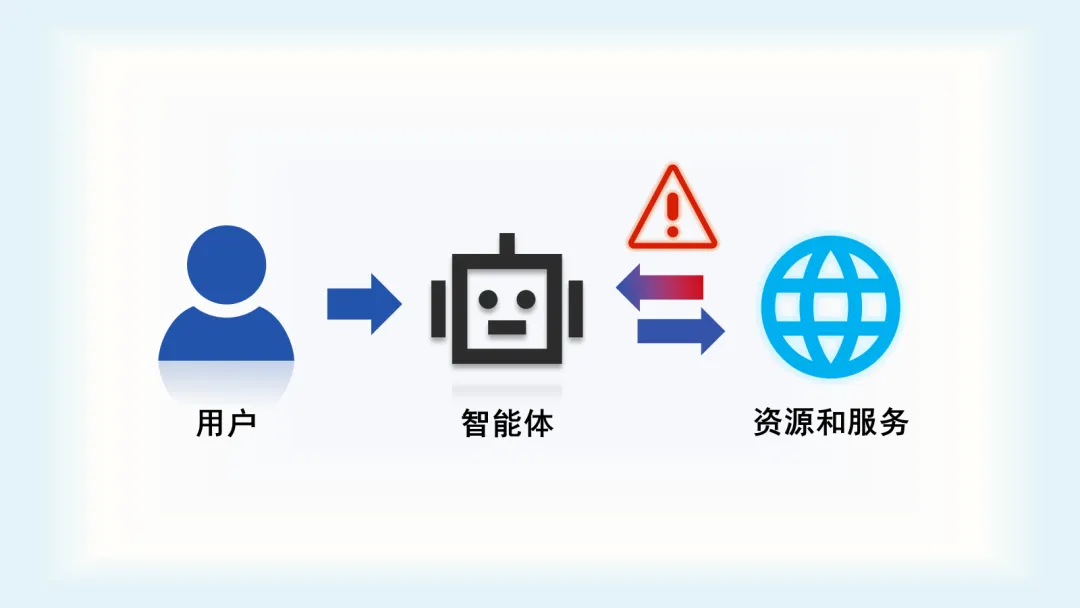
能力拓展,风险随之升级。为发挥更大效能,智能体被赋予更高的工具执行权限,其执行上下文也更为复杂和不可控。在整合外部资源的过程中,一旦有恶意内容或非预期行为被纳入决策链路,风险就可能在运行过程中持续放大,威胁系统整体安全。
于是,问题便不可忽视:当 AI 拥有“执行权”,如何在复杂交互中识别并阻断潜在风险?
智能体执行安全,白泽逐影保驾护航
工具调用机制为智能体的执行能力提供了支持,而 MCP(Model Context Protocol)则为这一机制提供了连接模型与真实系统的统一接口。然而,扩展智能体操作边界的同时,MCP 也开辟了新的风险入口:远程 MCP 服务的“黑盒化”,以及大量高风险行为的“运行时触发”特性,都使传统安全审计手段面临明显局限。
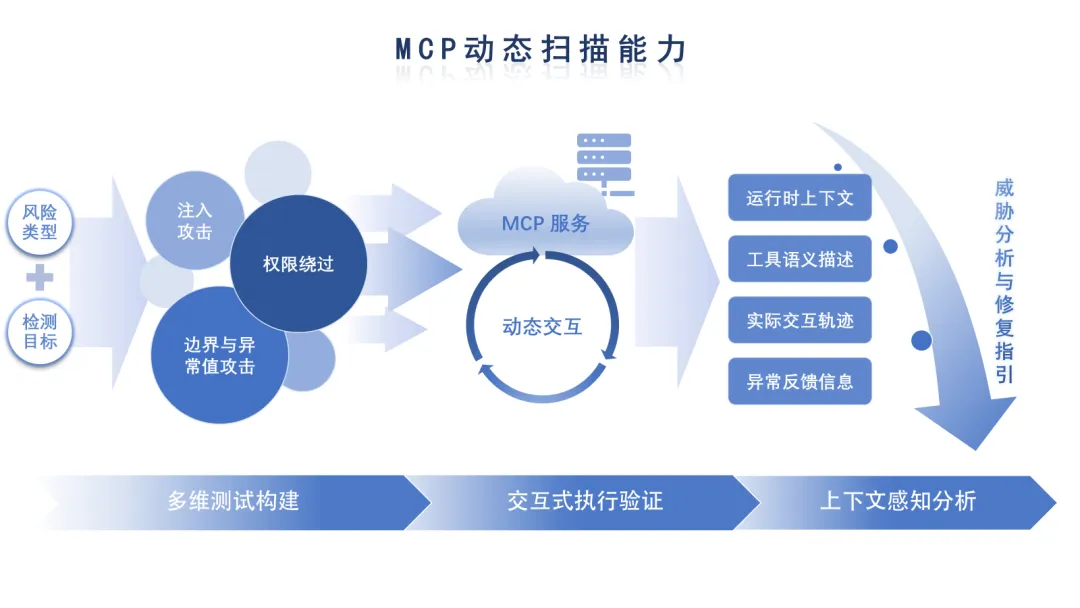
为应对上述挑战,复旦大学白泽逐影(Telltale)智能体安全研究团队打造了面向智能体的运行时安全风险检测框架,为智能体安全保驾护航。该框架通过“多维测试构建—交互式执行验证—上下文感知分析”的闭环,为 MCP 服务提供基于真实交互的安全扫描。目前,框架已覆盖工具投毒、命令执行等 8 类风险的识别,并支持用户自定义扩展风险检测项。
其核心亮点包括:
- 运行时风险洞察:无需源码,即可针对远程服务端进行交互测试
- 端到端自动化评估:极简配置,由智能体自主驱动测试与结果分析
- 多源风险深度分析:聚合多源信息,输出高可解释分析与修复方案
目前,这一核心能力已落地至腾讯 A.I.G(AI-Infra-Guard)平台,为其 MCP 服务风险检测模块赋能,实现运行时风险识别。

链接: https://github.com/Tencent/AI-Infra-Guard
白泽逐影(Telltale)智能体安全研究团队

白泽逐影(Telltale)智能体安全研究团队由杨哲慜副教授领衔,致力于研究大模型应用漏洞挖掘技术、构建面向新型智能化应用的安全攻防能力,为大模型应用的可信落地与稳健发展提供有力保障。过去一年中,团队已针对多类大模型应用产品开展了漏洞挖掘与安全检测工作,发现了数百个产品的安全风险,并及时向多家国内外企业进行了负责任披露,推动多项风险完成修复落地。相关成果已获得亚马逊、Anysphere、腾讯、百度、字节跳动、快手等头部企业的认可,并在业内产生了积极影响。未来,我们期待与产业伙伴携手探索大模型应用安全治理的更多可能,共同推动智能化软件生态的安全发展。