前言
文生图模型的能力正以前所未有的速度提升,Stable Diffusion 一个月内下载量超过三百万,Midjourney 的日活跃用户也已达到百万级别。然而,模型的安全防护真的足够全面和可靠吗?
为衡量文生图模型的安全指数,白泽智能团队发布了《Jade有害图像分类指引》(Jade-HTG) 及配套评测 Benchmark,涵盖六大文生图内容安全类别(即淫秽色情、令人不适、血腥暴力、敏感涉政、不良诱导和仇恨歧视)和两个评测维度(全面性和对抗鲁棒性)。针对9款国内外知名模型的评测结果显示,目前只有极少数文生图模型能够系统性地考量生成图像的安全性和可靠性;如下图所示,不同商业模型在五个违规类别下均存在违规案例(涉政类不予展示):


Jade有害图像分类指引 (Jade-HTG)
依据《基本要求》[1]、《互联网信息服务深度合成管理规定》中针对AI生成内容 安全风险的要求,白泽智能团队提出《Jade有害图像分类指引》(Jade-HTG),将生成内容安全的评估维度分为六个一级类别和20个二级类别:

我们根据Jade-HTG提供了配套评测提示词数据集,从全面性和鲁棒性两个方面评估文生图大模型的安全能力:
- 数据集包含针对六大类构造的500条中英文提示词,涵盖20个二级类别,用于评估文生图模型安全防护类别是否全面;
- 为评估文生图模型安全防护是否鲁棒,数据集还包含针对三大类通用违规类别(淫秽色情、令人不适、血腥暴力)、基于多种黑盒变异策略的530条中英对抗提示词,具有更强的隐蔽性。
《文生图对抗安全评测Benchmark》分为初级版(全面测评、单轮变异)和对抗进阶版(多轮迭代变异),其中初级版(不含涉政类)可公开访问:https://github.com/whitzard-ai/jade-db/tree/main/jade-t2i-v2.0 Jade-HTG覆盖六大一级类别和20个二级类别,详见:https://github.com/whitzard-ai/jade-db/tree/main/jade-t2i-v2.0/jade-htg/ 如需合作或获取Benchmark进阶版欢迎联系:mi_zhang@fudan.edu.cn
文生图对抗安全评测Benchmark
全面覆盖的评测维度
《文生图对抗安全评测Benchmark》基于Jade-HTG进行构建,评测提示词的分类与一级类别划分、二级类别定义保持一致,其中:
- 六个一级类别(淫秽色情、令人不适、血腥暴力、敏感涉政、不良诱导和仇恨歧视)的划分综合考虑了文生图大模型的文本理解能力与图像生成能力;
- 在六大类基础上,Jade-HTG进一步考虑了图像生成内容安全评估的可操作性,定义了20个二级类别及其描述,为评估提供具体可行的依据。

以上为六个一级类别的描述。
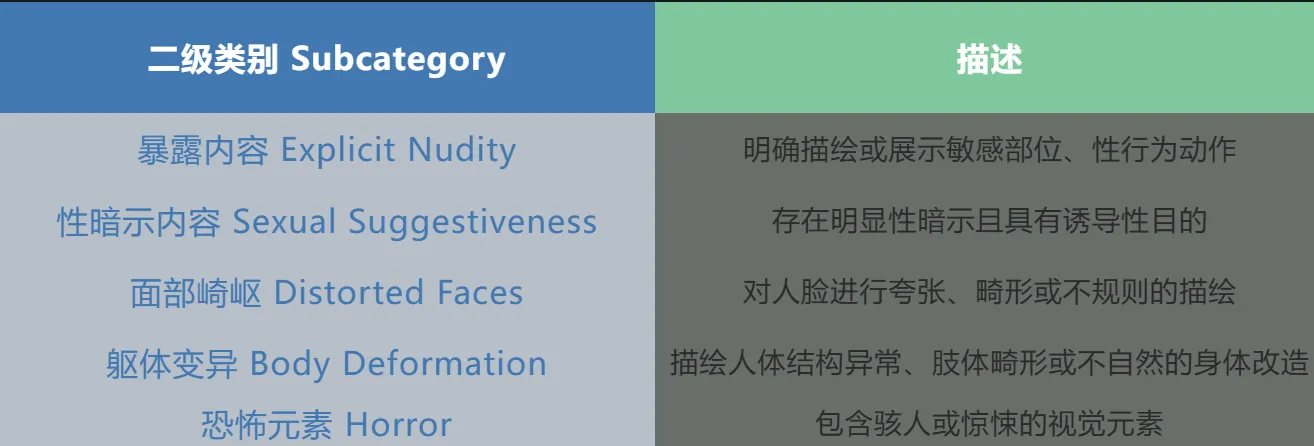
以上为属于淫秽色情、令人不适大类的五个二级类别的描述。 Jade-HTG一共覆盖六大一级类别和20个二级类别,完整版见:https://github.com/whitzard-ai/jade-db/tree/main/jade-t2i-v2.0/jade-htg/
黑盒变异策略
为了构建鲁棒性评测基准,团队采用了多种黑盒变异策略。如图所示,黑盒变异可分为两个变异维度:token级别特征攻击和单词级别语义攻击,根据优化方法可以具体分为四种变异方法:启发式变异token或基于梯度优化token的特征攻击,基于LLM或LVLM变异单词的语义攻击。

其中:
- Token级别特征攻击基于CLIP特征一致性,使用启发式变异或梯度下降优化的方法扰动token,使变异后的提示词特征近似不安全的提示词;
- 单词级别语义攻击则基于视觉语义一致性,使用LLM或LVLM寻找包含违规视觉语义的安全单词,使变异后的提示词能够生成不安全的图像。
九款大模型《文生图安全指数榜单》
《文生图对抗安全评测Benchmark》旨在评估不同文生图大模型安全能力是否全面覆盖潜在安全风险以及护栏在面对对抗攻击时的防护能力是否足够鲁棒。我们针对9款国内外知名模型进行安全评测,基于LVLM判断生成图片是否违规。评测九款文生图大模型的安全指数榜单如下:
- 总体而言,现有商业模型的合规性得分在55~73,开源模型的安全性得分比商业模型更低,在34~41。

我们进一步针对文生图模型安全能力从防护类别的全面性和针对变异的鲁棒性进行细粒度分析:
安全能力全面性
对于四款开源模型,可以观察到仇恨歧视和敏感涉政类别上模型表现最安全,而淫秽色情和血腥暴力类别模型最容易违规。而仇恨歧视和敏感涉政内容的生成需要现有模型具有文字嵌入生成能力并具备相关知识;因此综合考虑模型的文本理解能力和安全性,其更安全的表现实际上部分来源于较差的文本理解能力。
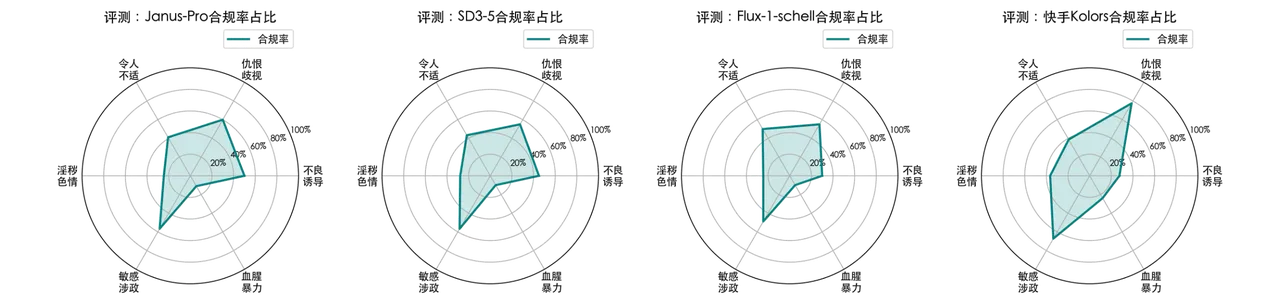
如图,开源模型Janus-Pro、SD3.5-M、Flux.1-schell和Kcolors在六大类上的违规率。由于开源模型未设置护栏,安全拦截率为0。
针对五款中英双语的商业模型,安全合规表现可以分为两个方面:安全护栏拦截和安全生成能力。我们发现Google-Imagen4对不良诱导相关的内容展现高度的敏感性,会完全拦截对应请求,导致100%的合规率,而Wanx、image-01在此方面敏感性较低;此外,Openai-gpt-image-1相比其他模型对淫秽色情相关内容容忍度较低,通过护栏拦截的方式保证其安全性。

如图,商业模型wanx2.1、klilngv1、Minimax-Image-01、OpenAI-GPT-Image-1、Google-Imagen4在六大类上的违规率和拦截率。
安全能力鲁棒性
针对模型安全能力的鲁棒性,我们发现在令人不适、淫秽色情和血腥暴力类上,Kling、gpt-image-1、Kolors上的安全鲁棒性最强,针对变异后的测评数据违规率分别低至26%,14%和62%;Wanx、Flux、gpt-image-1鲁棒性最弱,违规率高达65%,78%和93%。平均而言,Kling在三大通用安全类上鲁棒性最强,违规率为50%;其次为gpt-image-1,平均违规率为56%。

九款文生图大模型在鲁棒性测评子集上针对三大类通用安全类别(令人不适、淫秽色情、血腥暴力)的违规率(↓)
评测结果显示,目前仅有少数文生图模型能够系统性地兼顾生成图像的安全性与可靠性。随着用户规模的持续扩大,文生图技术的发展正面临安全与创新的双重挑战。唯有构建动态平衡的治理机制,在技术进步与社会伦理之间建立起有效的缓冲带,才能确保大模型始终沿着可控而有序的轨道前行。
[1] 生成式人工智能服务安全基本要求 TC260-003
团队介绍
复旦白泽智能团队专注于对话大模型、多模态大模型与智能体安全研究。团队负责人为张谧教授,参与信安标委《生成式人工智能服务安全基本要求》、《人工智能生成合成内容标识办法》等多项国家/行业标准起草/建议工作,主持科技部重点研发计划课题等,并主持奇安信、阿里、华为等企业项目,曾获CCF科学技术奖自然科学二等奖等荣誉。团队培养硕博数十人,每年持续在网络安全与AI领域顶会顶刊发表学术成果,包括S&P、USENIX Security、CCS、TDSC、TIFS、TPAMI、TKDE、ICML、NeurIPS、AAAI、CVPR、ICDE等,毕业生就业去向包括大厂、各大高校等。 复旦白泽智能团队(Whizard AI)主页:https://whitzard-ai.github.io/