现代软件开发中,动态编程语言(如Python、JavaScript和PHP等)因其灵活高效的特性而被广泛应用,但这也给静态语义分析带来了大麻烦:传统静态分析工具往往依赖于对程序行为的过度保守近似,导致结果中混入大量无意义的告警与误报,真正的安全问题反而被埋没。
为了解决静态分析的这一痛点,来自复旦大学系统软件与安全实验室的研究团队提出了LIAN,一个面向多语言的全新静态分析基础设施,它通过抽象解释精确地“重建”程序的内存语义,重新定义了静态分析动态语言的可能性。实验表明,LIAN 在精度和可扩展性上都优于现有方案,为动态语言的高质量静态分析提供了可落地的新方法。
01 前言
在现代软件开发中,动态语言以其高灵活性、低开发门槛和庞大的生态,成为了云计算、AI等系统的首选。然而,这种“灵活性”对安全分析和质量保障工具来说,却是一场灾难。
动态语言可以在运行时随意修改对象结构、动态加载模块、拼接执行代码(如 eval、exec),让程序的真实行为超出静态分析的掌握范围。传统的静态分析工具要么选择保守估计,导致结果中充斥无关信息;要么尝试强行精确建模,却付出极高的性能代价。结果是——分析结果“全是噪音”,真正有用的安全线索反而被淹没其中。
为了解决这一长期困扰安全社区的痛点,我们设计了 LIAN,一个能够针对动态语言进行高精度语义分析的创新分析基础设施。它不依赖动态执行信息,而是通过抽象解释重构出程序的可能状态,从而在静态分析的框架下,实现更接近真实执行语义的结果。
02 研究背景:为什么动态语言的静态分析如此困难?
Python、JavaScript、PHP……这些动态语言让软件开发变得更高效、更灵活。变量无需预先声明类型,对象可以在运行时随意扩展属性,函数甚至可以被动态替换——正是这些“灵活”的特性,让程序写起来轻松,却让静态分析工具异常头疼。
看一个简单的例子:
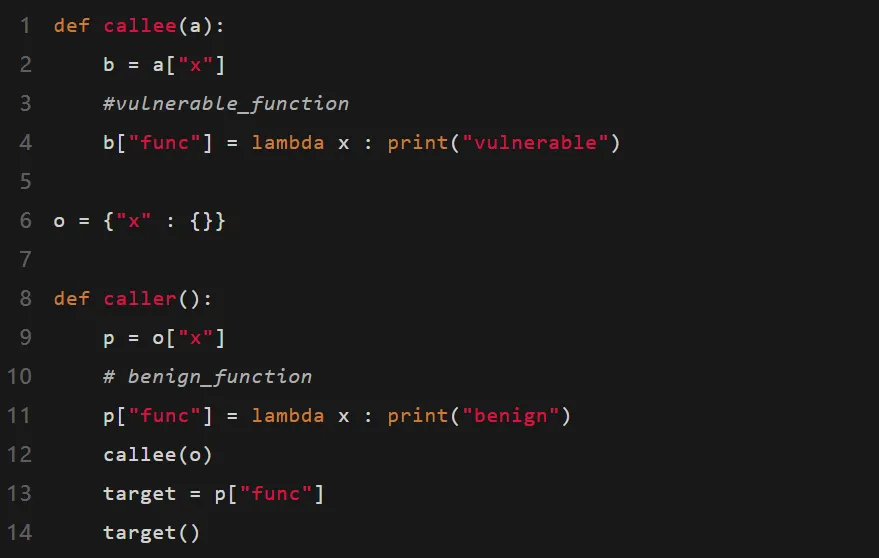
这段代码中包含了多种典型的动态特性:
- 动态类型与结构变化:变量 o、p、b 的类型和属性结构都在运行时才确定;
- 动态属性访问:o[“x”]、p[“func”] 这样的键访问方式使分析器难以静态枚举所有可能字段;
- 对象别名(aliasing):p 和 o[“x”] 实际指向同一个对象;
- 跨过程状态修改:callee() 内部通过 b[“func”] 修改了 caller() 中的同一对象,使函数行为在调用链中被动态替换。
在这段代码中,p和o[“x”]互为对象别名,指向同一片内存。callee()修改了该对象的内部字段,使得原本的安全函数被替换成了“vulnerable”函数。最终调用 target()时,程序行为发生了变化。
问题是,大多数静态分析工具根本看不出来。它们要么过于保守,把所有可能的函数都混在一起,结果误报满天飞;要么缺乏跨函数的内存追踪,完全漏掉这类跨过程的修改。更糟的是,这类“别名修改”在真实动态语言项目中无处不在,导致分析结果既不精确也不可靠。
03 研究思路:LIAN 如何破解难题?
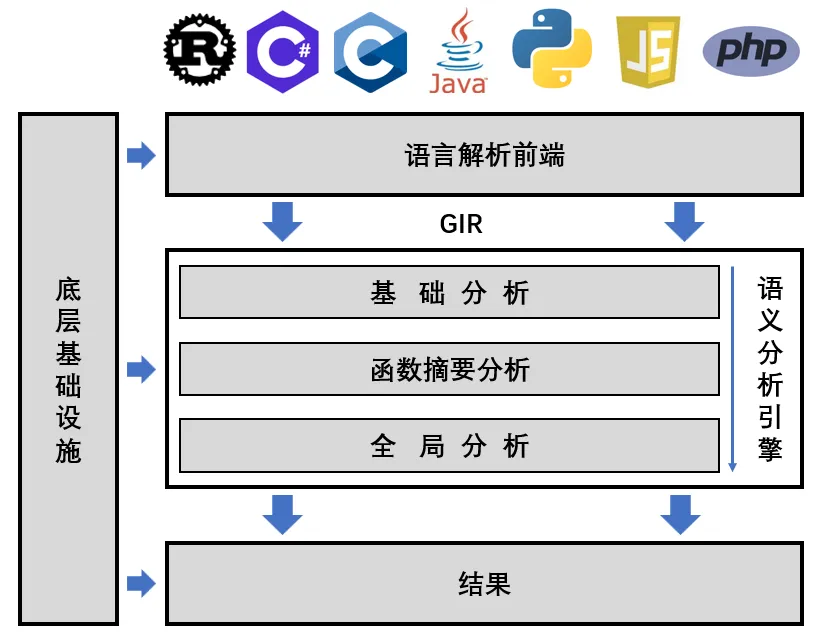
要想在动态语言中实现高精度的静态分析,首先要回答一个核心问题:当代码的行为是动态变化的,我们还能否在静态层面重建它的真实语义?
LIAN的核心思想是:动态语言的运行时内存状态蕴含了解析程序真实语义的关键信息。即便无法运行程序去拿到每一个 concrete snapshot,我们也可以在静态层面重构出等价的内存状态抽象,用它来驱动更精确的语义分析。为此,我们设计了两大关键技术:
- 状态化抽象解释(State-centric Abstract Interpretation)
把分析对象从“符号”提升到“内存状态”:LIAN 不再只跟踪变量名和语法位置,而是构建一套描述对象、字段、数组位置以及它们相互依赖的抽象状态模型(state)。
- 分支敏感 + 版本化(Copy-on-Change):每次对对象的修改都会产生一个新的状态版本,避免将不同执行路径的结果盲目合并,从而保留“修改前/后”的语义差异。
- 状态级别的 Def/Use 分析:在 state 粒度上维护 def/use bit vectors,可精确判断某一时刻“哪个状态是活跃的/最新的”。
- 基于状态 ID 的别名解析(self-Grasp):为每个状态分配唯一 ID,并通过状态级别的追踪把别名写入与读出连成一条线,静态地识别跨变量、跨函数的共享与覆盖关系。
- 效果:在遇到 p = o[“x”]、callee(o)、p[“func”] = … 这种跨过程别名写入场景时,LIAN 能静态推断“谁在什么时候把某字段改成了什么”,避免传统工具的模糊合并或漏报。
- 自底向上的状态摘要(Bottom-up State Summarization)
把函数当作状态变换的模块化单元来总结与复用:为避免在全程序范围内爆炸式地复制状态,LIAN 在函数级别抽取“状态摘要”,把一个函数对其参数和外部对象所做的状态变换压缩成一个可应用的模板。
- 函数级摘要:LIAN 将每个函数看作一个“状态变换单元”,对其输入参数和全局对象的状态变化进行建模,生成对应的摘要(summary)。摘要记录了该函数对内存状态的影响,而非执行路径的细节。这样,当函数被多次调用时,无需重新展开分析,只需复用其摘要。
- 自底向上分析:LIAN 先分析底层函数(无调用者或依赖较少者),生成稳定摘要;然后逐步将这些摘要应用到更高层函数。通过这种自底向上的策略,LIAN 能够在不牺牲精度的情况下,快速构建跨过程的全局语义视图。
- 状态映射:在调用点应用摘要时,LIAN 会把被调函数中的抽象状态映射到调用者的实际对象空间,从而确保不同上下文中的内存引用保持一致。这种映射使得跨函数修改(如参数别名写入)能够准确传播回上层调用环境。
04 总结
LIAN是复旦系统软件与安全实验室自主研发的多语言、高精度代码静态分析框架,能够理解复杂代码中的数据流、指向关系等深度代码语义,为代码安全检测、漏洞分析与程序理解提供坚实基础。
目前,LIAN 已正式开源。开源版本集成了核心分析引擎与通用中间表示(GIR),并提供了对 Java、Python、JavaScript、PHP 等语言的统一支持。我们诚挚邀请大家试用、交流与共建,一起推动高精度语义分析技术的发展。
LIAN仓库地址:https://gitee.com/fdu-ssr/lian