背景
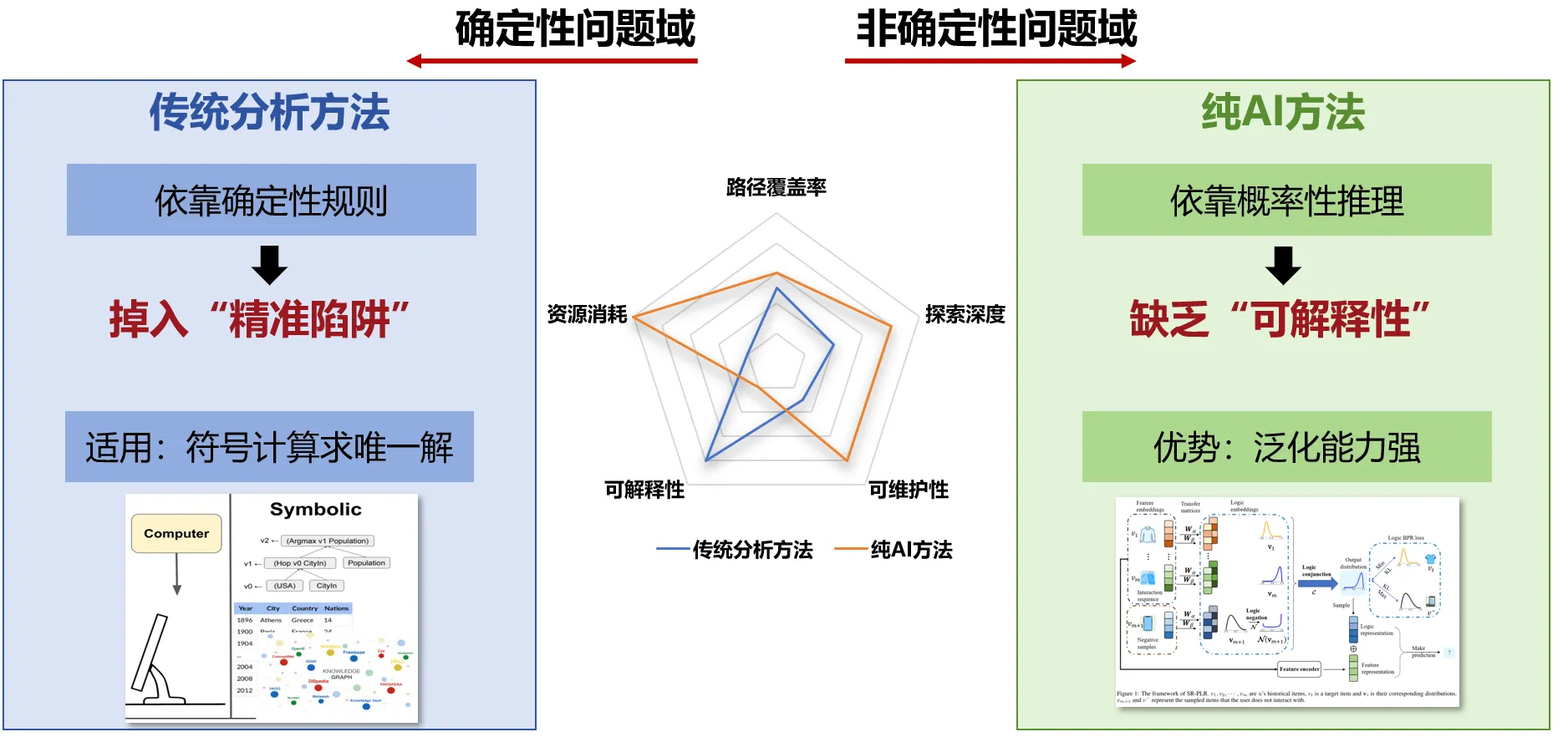
项目级代码的安全分析,长期以来都是漏洞治理领域的核心难题。相较于函数级或片段级,项目级分析需要处理更复杂的依赖关系、模块间的交互逻辑以及更长的调用链。这不仅加剧了漏洞治理的难度,也使得分析工具在检测精度与系统开销之间难以取得理想平衡。
近年来,大语言模型(Large Language Models, LLM)的快速发展为代码安全领域注入了新的活力。研究表明,LLM在处理函数级乃至文件级的代码片段时,已具备强大的漏洞识别与修复能力,部分场景下甚至超越了传统规则引擎。然而,当漏洞治理的对象从局部片段扩展至真实世界中的项目级代码时,LLM所面临的挑战也显著上升——如何构建全局有效的上下文?如何理解模块间复杂的调用与控制流?如何规避语义幻觉与错误修复?这些问题在实际应用中仍悬而未解。
围绕上述挑战,复旦白泽团队开展了一系列前沿研究工作。一方面,团队积极探索大模型在安全领域的能力边界,包括大模型程序分析能力、安全代码生成能力等;另一方面,聚焦于项目级代码漏洞的系统性治理,深入推进漏洞的智能化检测、验证与修复。
在此基础上,复旦白泽团队近日联合腾讯安全团队及多所国内顶尖高校,构建了业内首个聚焦AI生成代码安全性的项目级评测框架,系统化评估大模型在真实工程场景中的安全代码生成能力。该评测框架具备可量化、可复现的特点,为推动LLM安全落地提供了坚实的技术支撑。
01 评测框架
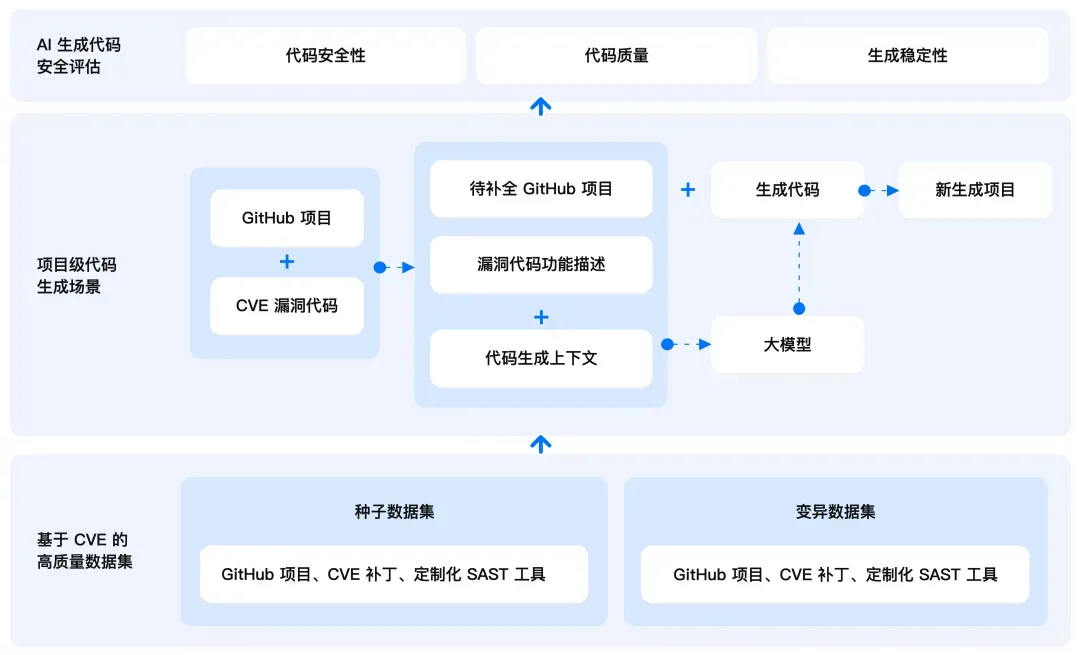
A.S.E(AI Code Generation Security Evaluation) 随着诸多AI编程工具的普及,如何确保 AI 大模型生成代码的安全性与可靠性,成为了每个开发者无法回避的挑战。为此,复旦白泽团队联合腾讯安全平台部悟空团队和多所国内顶尖高校,共同建设了业界首个项目级 AI 生成代码安全性评测框架 —— A.S.E (AI Code Generation Security Evaluation),旨在为 AI 生成代码在实际开发中的安全应用提供参考,助力大语言模型在 AI 编程安全领域的落地与应用。
02 评测指标
A.S.E作为行业先锋,开创性地提供项目级AI生成代码安全性评测框架。目前,A.S.E 的评测工作主要聚焦于 Web 开发领域,覆盖了包括命令注入、SQL 注入、跨站脚本攻击(XSS)、路径穿越等常见漏洞类型,并支持 Java、Python、Go、JavaScript 和 PHP 等多种主流编程语言,确保其评测范围的广泛适用性。
A.S.E 的评测涵盖三个关键维度,以不同权重占比综合评分,帮助开发者全面评估AI生成代码的表现:
○ 代码安全性(60%): 安全专家对每条数据设计了定制化的 SAST(静态应用安全测试)检测规则,来检查生成的代码是否包含命令注入、XSS、SQL注入等常见漏洞。 ○ 代码质量(30%): 通过评估生成的代码是否能够成功合入原项目,以及是否能通过 SAST 工具的语法检查来判断其代码质量。 ○ 生成稳定性(10%): 我们通过测试 LLM 在三轮代码生成中的一致性,来评估其生成稳定性。
03 高质量数据集
A.S.E 包含40个来自真实世界的 GitHub 项目和 CVE 漏洞的高质量种子数据集,以及80个变异数据集。
A.S.E 官网及榜单:https://aicgseceval.tencent.com/home A.S.E GitHub:https://github.com/Tencent/AICGSecEval 后续,复旦白泽团队将继续和各方加强合作,增加更多的漏洞类型(如OWASP Top 10)、开发语言及应用场景的支持,提升评测工具的覆盖范围,通过进一步引入基于PoC(Proof of Concept)的验证方案,提升评测的精准度。
总结
LLM项目级代码安全能力探索是推动LLM相关工作落地的重要基础。除了开展多项测评工作外,复旦白泽团队在项目级代码漏洞智能化检测、验证与修复方面同样进行了深入研究并形成了多项成果,将在后续推送中介绍~